
GENERATED VIDEO WORK
LIMINAL PHANTOM
Animation + Trained Model, available for free on Patreon.
The feeling of being connected to another without having ever known them. Making eye contact with a passing wild animal in the forest. Seeing a familiar stranger in a dream.
The images from this film were created with the Flux.1-dev LoRA "Liminal Phantom" and animated with WAN2.2-I2V-A14B. The model is twice distilled and deliberately overfitted. The first synthetic dataset was built from a multi-LoRA pipeline in ComfyUI, used to train the initial version. That model then fed a second image pipeline to generate the training data for the final version, the one that produced this look. Trained with Ai toolkit on Runpod.
Once generated, the images were brought into a WAN2.2 workflow in ComfyUI with a chain of motion models to facilitate the constant speed of the camera moves and particle systems. The final output was filmed on a CRT and composited with the original renders.



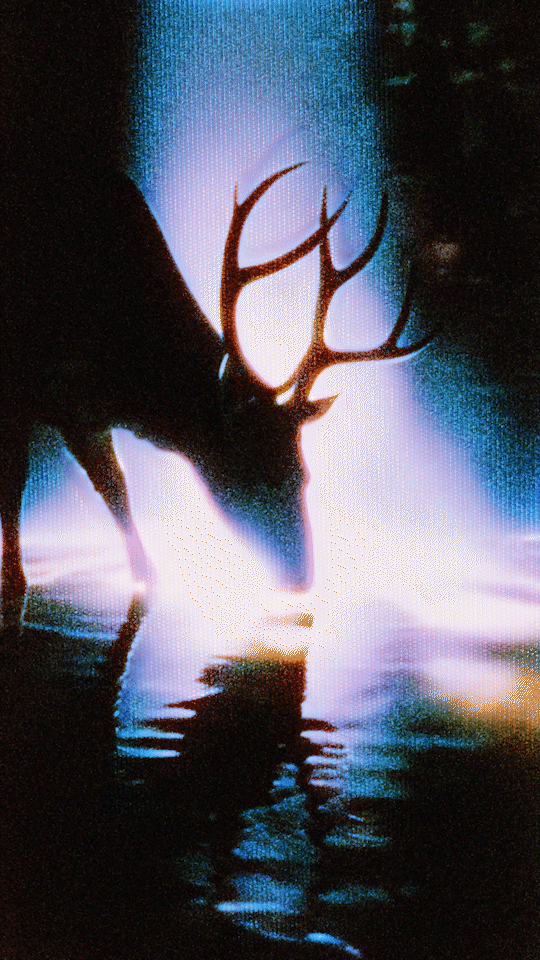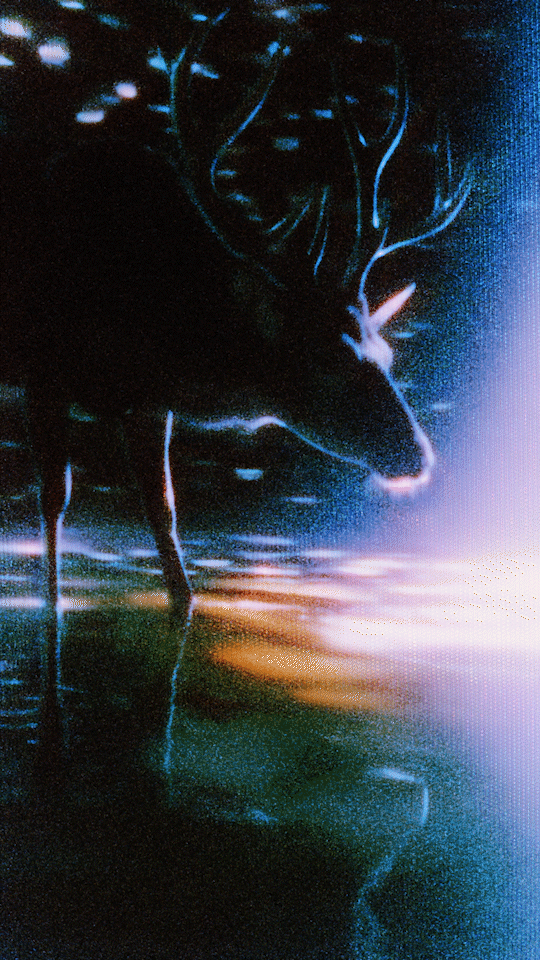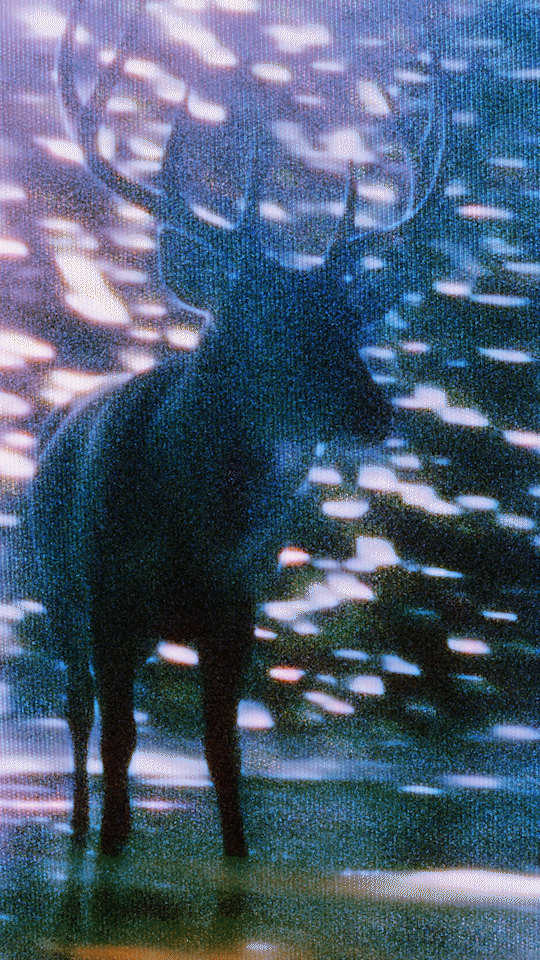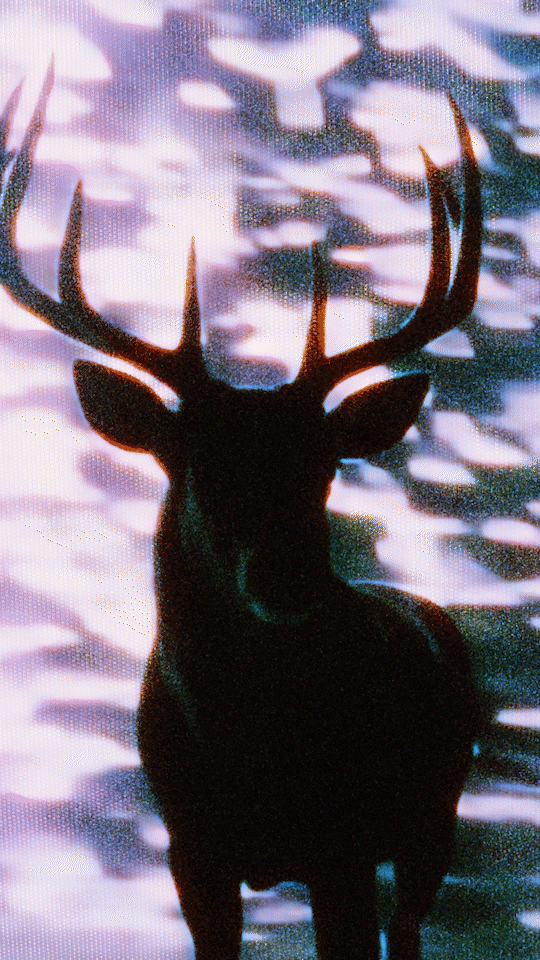
ComfyUI WAN Fist-Frame + Last-Frame I2V Workflow
First-Fr.
LAst-Fr.
Final Clip
WORLD OF VULCAN
Short Film + Model | Commissioned by Eleven Labs | Fal AI sponsor prize at the 2026 Chroma Awards
A poetic visualization of a fantasy world from thousands of years in the past.
The imagery in the film was created using a LoRA (16_anam0rph1c) l built on the Flux1-dev architecture. The model was trained on wide-screen 16mm imagery shot with vintage anamorphic glass. It produces barrel distortion, edge aberrations, and blooming highlights that feel analog and cinematic. The LoRA is available for free on Patreon.
This is part of the development process for a Greek mythology interim-narrative longform project I'm writing.
Traditional production has always been rigid, with clear separation between writing, pre-production, production, and post-production. With generative video, those lines become as blurred as the creator desires. It's been a complete reframing of the process; being deep in pages of script, hitting a wall, hopscotching over to production to visualize the world, jumping back into prep to outline a shot list before the pages are written, returning to the screenplay to continue writing, all while the project is open in Premiere where I'm not only cutting picture but experimenting with a late-post color workflow, training models on camera log and testing textural film emulations.
The beauty in this is how the process of creating a film can be done in a harmony that reminds me of painting a picture; making thumbnails while mixing colors, going back over mistakes, mono-y-mono with the canvas - where there are fewer barriers of recourses, logistics, and mobilization - between the maker and the made.








FLUX Generated stills used as I2V keyframes in "World of Vulcan"
FILM TRAILER (PROCESS)
Process video for an upcoming feature film teaser, in collaboration with DOGMA and Red Joint Film.
The production will start shooting in 2026 and deploy a hybrid of AI and location filming, though the teaser was fully generated with AI.
For this project, I was the lead AI artist and given a feature-length screenplay to create a 90-second trailer for. I created the visual language of the film during a period of R&D, where built a custom multi-model pipeline inside ComyUI that uses trained models to create a gritty, intense aesthetic that feels both cinematic and candid. I then executed the generation of all the AI images and videos. There were many rounds of revisions for shot sequences, composition design, lighting design, characters, costumes, locations, and animations.
VELOCIUM

First place title prize winner for Project Odyssey season 2, 2025.
Connection and isolation; each can be a prison or an escape, both are needed to understand one another.
When I wrote this in 2023 it was a journal entry that I had no intention of making into a film, it was an emotionally charged vent. When I began to discover the possibilities of creating animation with Machine Learning tools, I thought this would be a good piece of writing to turn into an animated film.
CREDITS
Written, Animated, Edited, and Directed by Calvin Herbst @calvin_herbst
Sound Studio: ADY.AUDIO @ady.audio
Sound Design and Mix by Daryn Ady @ydanyrad
Audio Producer Kamilla Azh @kamillazh
Song "Falaise" by Floating Points
ComfyUI Flux workflow with multi model LoRA pipeline and upscaling used to create the images in "Velocium"
PROCESS
-Images were generated using Text to Image with the Black Forest Labs FluxDev base model via comfy UI with tweaks in Adobe Photoshop.
-Images were animated using various Image to Video tools, including: Kling 1.6, Kling 1.5 start/end frame, Hailou, Haiper, Runway, and Luma Dream Machine.
-Additional assets were generated from Gaussian splats using Luma and processed in ComfyUI with Animatediff, IPadatapers, and Controlnets.
-Texture, Grain, and color were added with Dehancer-Pro in Davini Resolve and Adobe After Effects.
-Voiceover was created with Eleven Labs.
-The image generation model pipeline used a mix of open-source and custom-trained LoRAs.
-The LoRAs in the pipeline included training data from past and modern animation, live-action, photography, concept art, and experimental digital imagery.
-Some of the LoRAS I trained were distilled and trained on generated images via a separate model pipeline.
-The software, workflows, and custom nodes used in the generative image process were based completely on open source tools, built by those who were willing to give away what they created for free, using repositories like Civitai, Huggingface, and GitHub.

start frame

start frame

start frame

start frame

end frame (edited prompt, same seed)

end frame

end frame (same prompt, new seed)

end frame (same prompt, new seed)

final shot

final shot

final shot

final shot
Start and End Frame Image to Video
The above shots were created in Flux. When I found a good start frame, I would either run the workflow with the same parameters and find a new seed for a similar end frame, or run the same seed with an altered prompt.
Changing either only the seed, or prompt slightly allows for an end frame that is similar enough for a smooth transition while still being different enough to create a dynamic shot.
1. 3D camera moves in splat

2. 3D camera moves in splat

3. Generated Asset (T2I>I2v)
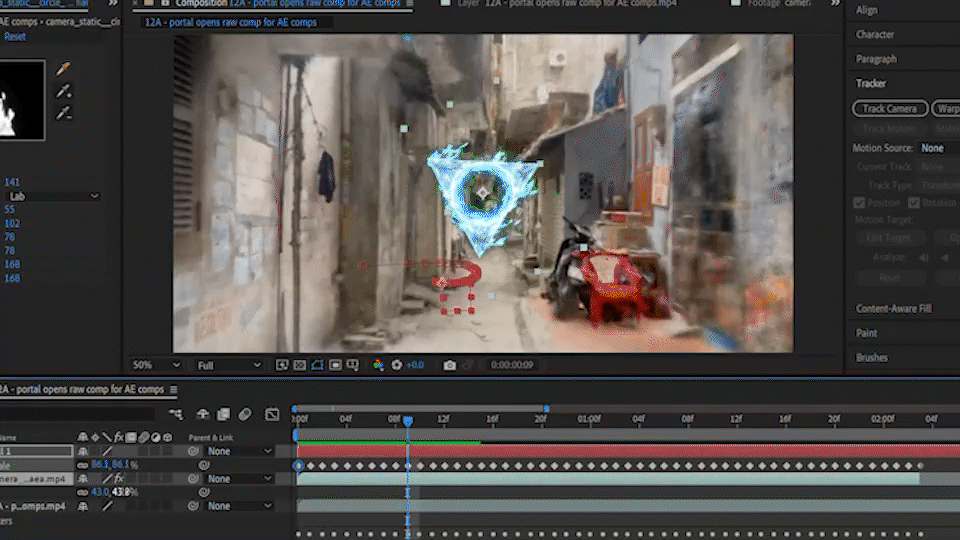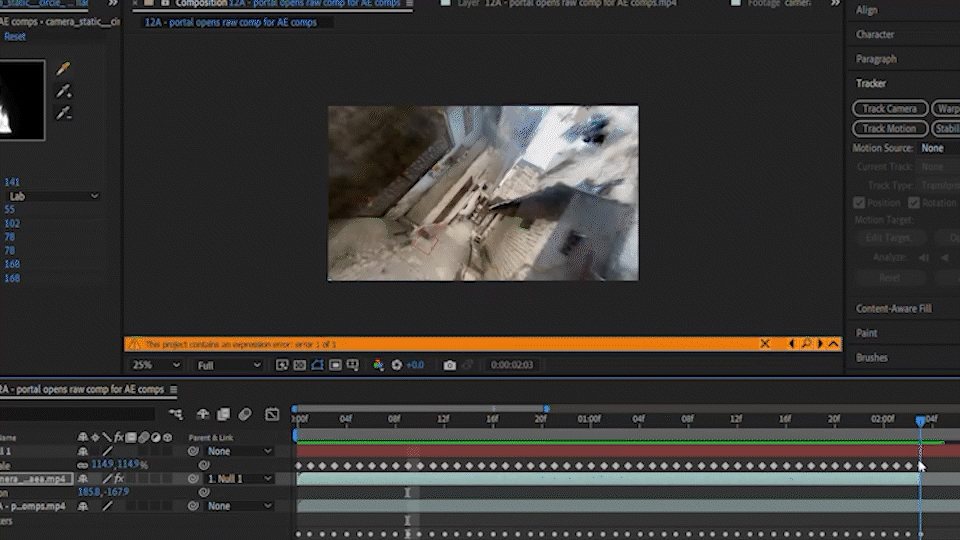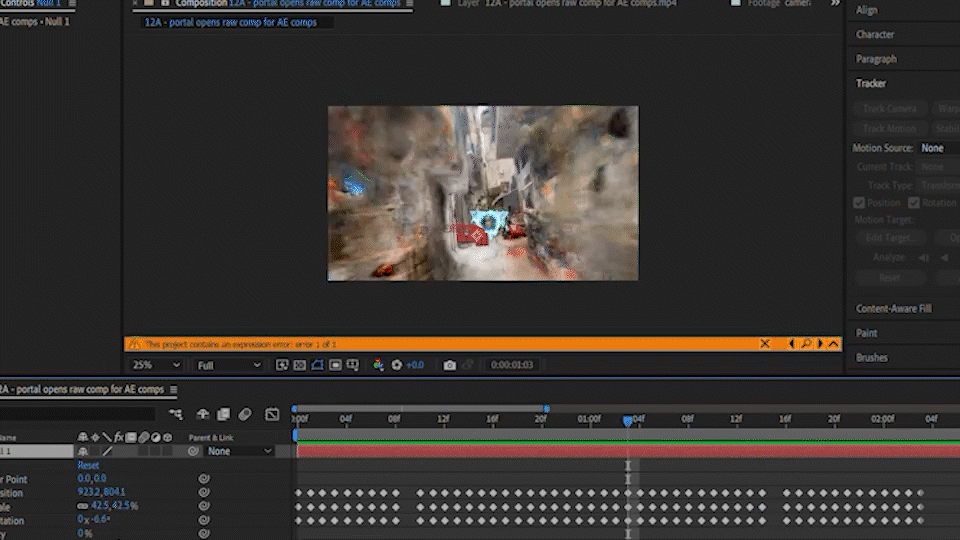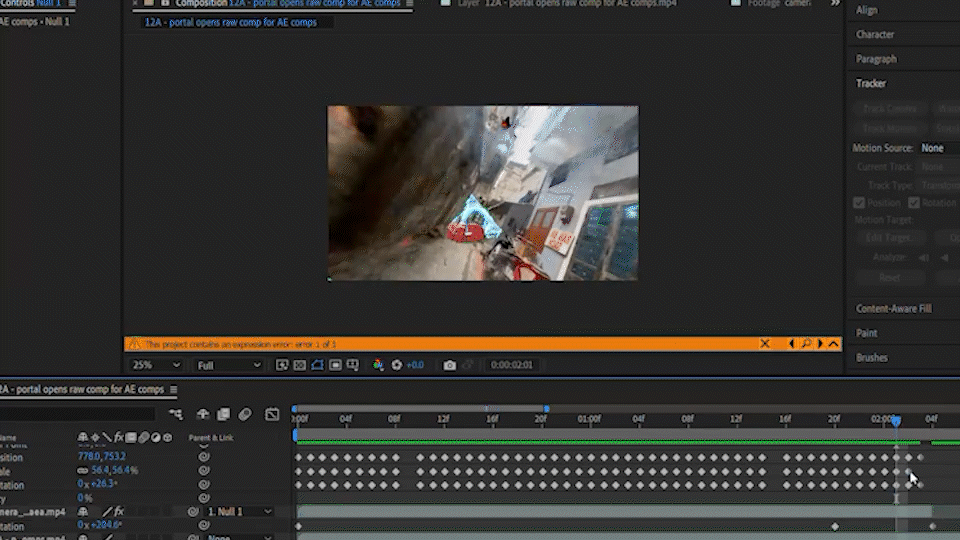
4. After Effects Comping

5. Comp for V2V

6. Final Output Ran Through SD1.5 AnimateDiff V2V
3D Video to Video (V2V) Process
I created 3 different gaussian splats (1,2), then animated a 3D camera inside the scenes so that they would flow together.
I used a Flux Text to Image workflow to create a portal asset against a green backdrop (3) and animated it with a separate Image to Video workflow. I took the Animated asset and comped it into the POV 3D camera videos in After Effects (4,5), than ran the comp through an Animate Diff V2V workflow (6).
SALESFORCE LOBBY
Installation | Stagwell (Parent) Left Field Labs (Agency) Salesforce (Client)
3D Video to Video Transformation.
I took inputs from a 3D/rigging/compositing team and used Comfy as a textural render engine, turning grayscale comps into dreamy animated cloudscapes. Tuned the Video to Video 3d Pipeline to deliver textures that balanced photorealism and animation to deliver a 8x 2-minute looping renders that played on a three-story floor-to-celing installation at the Salesforce headquarters lobby in Dublin.


Featured in the 2025 "Made with ComfyUI" showcase
Installation at SalesForce Headquarters in Dublin






Process: 3D assets to final clips with ComfyUI as V2V render engine.
VIDEO CONCEPT ART
A collection of my favorite shots out of 50,000+ images generated across various projects in 2025
Creating quality AI videos relies primarily on generating exceptional still images, which later get used in a separate image-to-video process. I found that using popular paid service image generation tools, or even untuned open source models, always yielded outputs that looked more like a stock photo than a still from a movie. It doesn't matter if the words "cinematic" and "shallow depth of field" are used in the prompt; the base models sample from vast datasets, hundreds of millions of images - more than a single person can ever see in their lifetime - resulting in outputs that feel too much like a "collective average" of every image ever made. It's like mixing all the colors of paint on a palette and ending up with some form of dull brown or grey.The, lighting, characters, compositions, and fine grain textures in this reel were only possible with a combination of LoRAs I trained thanks to open source repositories like Hugging Face, GitHub, and Civitai. I conducted extensive A/B tests in ComfyUI, locking seeds and testing model strength combinations down the hundredth of a percent, sometimes stacking 10 LoRAs together at a time, then making X/Y grids of every scheduling + sampling combination across multiple guidance scales.
FLOWERING PEOPLE
The internal expressed externally, through petals, stems, and leaves. Custom trained lora on my Artwork used in a fine tune Flux pipeline to create the imagery. Videos created using WAN 2.1 14B.
Presented theory and process used to create "flowering people" at the June 2025 ComfyNYC meetup, where I spoke about the importance of open source model pipelines, training philosophy, and workflow function.
PENCIL SKETCH
A meditation on solitude, created with a three-base-model workflow utilizing trained LoRAs.
featured in the ADOS exhibition hosted by Banadocco at RNA studio in Lisbon.
Trained a Flux LoRA on impressionistic pencil sketch style and fine-tuned it with 6 other LoRAs in Flux (1-1.5).
Used the Flux image outputs with WAN2.1_I2V_14B to create videos (2-2.5). Ran the WAN video outputs through an experimental Flux V2V workflow that utilizes Animatediff to re-sample each frame with a different seed back inside the original image model pipeline (3-3.5); allowing every frame to be slightly different as if hand drawn, and re-gaining the fine grain paperly textures of the training data that was lost in the WAN video model.




On Site Media from "Pencil Sketch" in the 2025 ADOS exhibition, hosted by Banadocco at RNA studio in Lisbon.
1. Flux T2I workflow

1.1. Flux still

2. WAN2.1_14B I2V Workflow

2.1. WAN Video from flux still

3. Flux V2V ReSampling Workflow

3.1. Flux ReSample from WAN video

1.2. Flux still

1.3. Flux still

1.4. Flux still

1.5. Flux still
2.2. WAN Video from flux still

2.3. WAN Video from flux still

2.4. WAN Video from flux still

2.5. WAN Video from flux still
3.2. Flux ReSample from WAN video

3.3. Flux ReSample from WAN video

3.4. Flux ReSample from WAN video

3.5. Flux ReSample from WAN video
GERTHSEMANE
A collection of my favorite shots I created for the music video "Gerthsemane" by Car Seat Headrest
Directed by Andrew Wonder
Trained Flux LoRAs from the film's raw camera data to generate visuals that match the style and characters, then used a separate closed-source Image to Video process to turn the stills into video.




1. Cast training data - Alexa Mini Camera Footage - (4 of 30)




Generated Images using trained Flux LoRA(1)




2. Cast training data - Alexa Mini Camera Footage - (4 of 30)




Generated Images using trained Flux LoRA
Generated Images using trained Flux LoRA(2)




3. Style training data - Alexa Mini Camera Footage - (4 of 30)




Generated Images using trained Flux LoRA(3)
CLOUDS
ComfyUI workflow with LoRAs, IPAdapter, AnimateDiff, Motion LoRA, Prompt Scheduling, Depth Map, and OpenPose

ComfyUI workflow with LoRAs, IPAdapter, AnimateDiff, Motion LoRA, Prompt Scheduling, Depth Map, and OpenPose

1. falling asset for comp

2. Rising asset for comp

3. bg asset for comp

Final comp for AnimateDiff V2V (1+2+3)
MAGIC CONCH
Video to video workflow in ComfyUI with LoRAs, IPAdapter Embeds, AnimateDiff, Controlnet, and Latent upscaling.

1. Hands asset for comp

2. Conch asset for comp
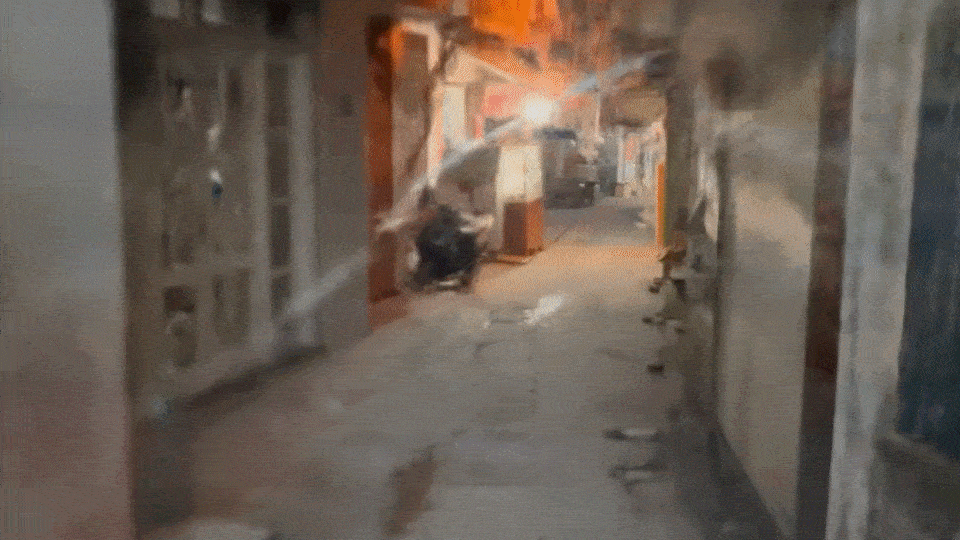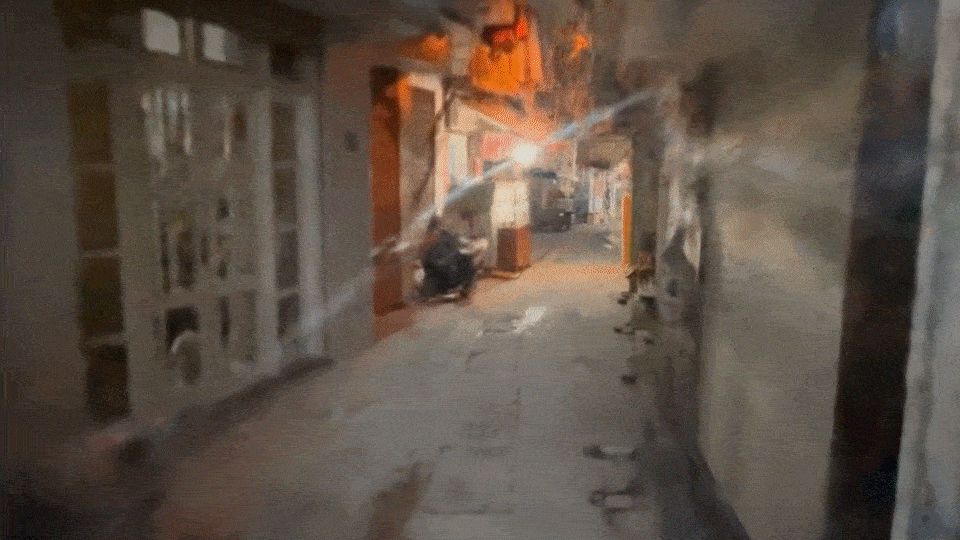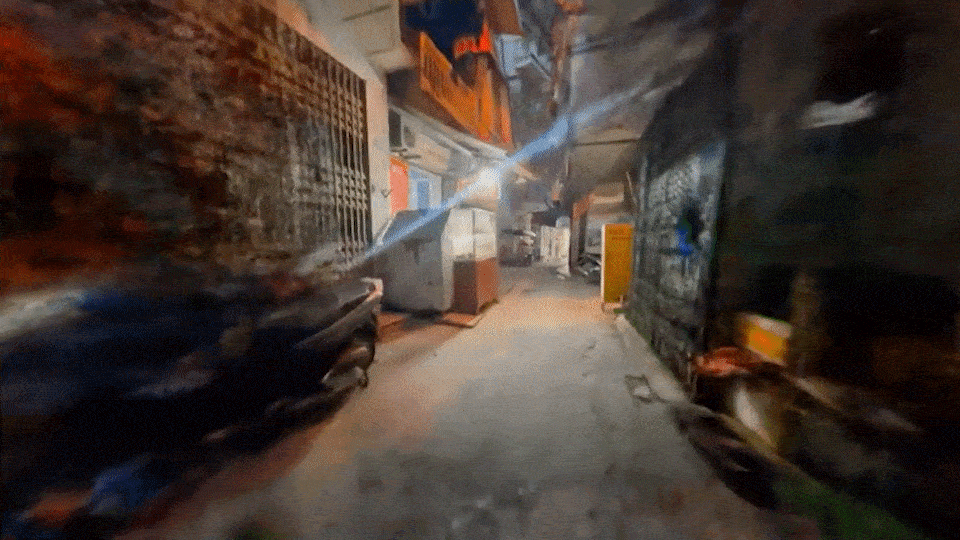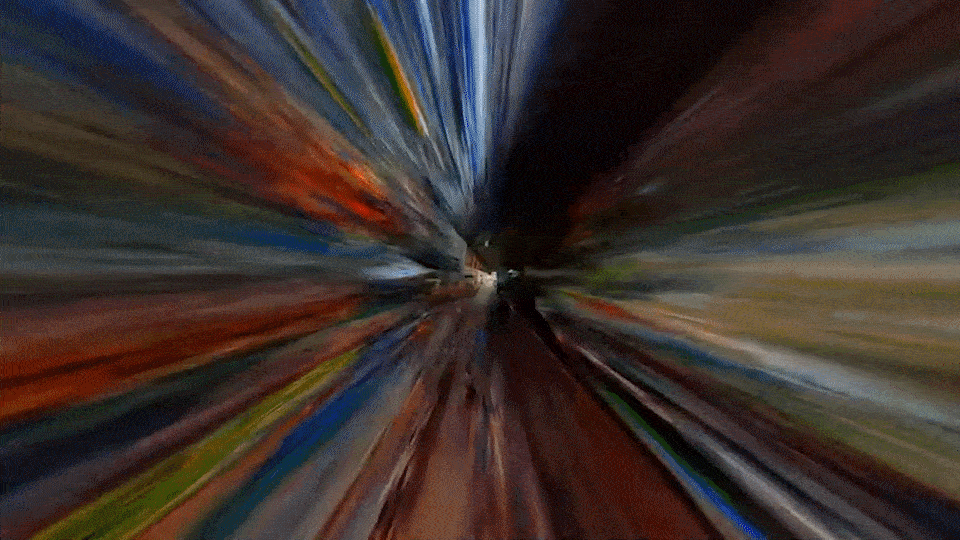
3. bg asset for comp

Final comp for AnimateDiff V2V (1+2+3)
TIMESCAPE
An escape from reality through an endless loop, created with images using a custom trained Flux Lora.
BUTTERFLIES
A feeling visualized as a texture, created in ComfyUI with AnimateDiff, IPAdapter Embeds, and Prompt Scheduling.
GOODBYE FANTASY
A poem about letting go of love delusions, created with animated Gaussian Splats, V2V, and ElevenLabs
WATERCOLOR DANCE
A choreographed performance about growth into womanhood, created in ComfyUI with AnimdateDiff and Controlnets

Dancing asset for comp

Bg Asset for comp

Final comp for AnimateDiff V2V
VIDEO STYLE TRANSFERS
Various explorations of AnimateDiff with controlnets and IPAdapters using Gaussian splats as input video
AUDIO REACTIVE ART
Melting patterns of the abyss, created in ComfyUI with Yann Audio Reactive Nodes, IPAdapter Embeds, and control

FALLEN ANGEL
A reflection on the cycle of birth and decay, created in ComfyUI with IPAdaper Embeds and AnimateDiff

IN AND OUT OF THIS WORLD
A depection of what it feels like to be with somebody special
This was one of my early AI creations. I used Gaussian splats of two oil bottles from my kitchen to block out a camera move between two figures, then used Luma Gen 2 with a reference image from Midjourney to style transfer the rudimentary scene into two human bodies. I interpolated two different outputs and did a simple comp and retime in Premiere. To soften out the textures from the early video models, I filmed the output on a screen with a 2005 Kodak ccd digitial camera.
FLORA LOGO ANIMATION
Logo Animation created in ComfyUI with LoRAs, AnimateDiff, IPAdapter, Controlnets, and a simple motion graphic vector as the source video input.

